Abstract
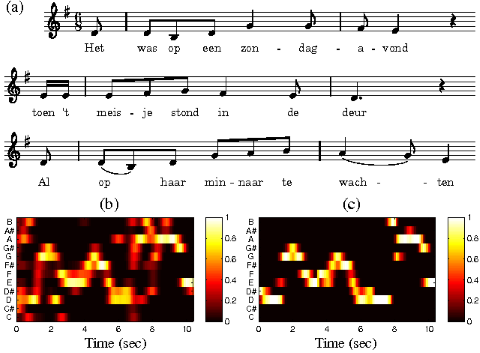
In this paper, we introduce an automated procedure for segmenting a given folk song field recording into its constituent stanzas. One challenge arises from the fact that these recordings are performed by elderly non-professional singers under poor recording conditions such that the constituent stanzas may reveal significant temporal and spectral deviations. Unlike a previously described segmentation approach that relies on a manually transcribed reference stanza, we introduce a reference-free segmentation procedure, which is driven by an audio thumbnailing procedure in combination with enhanced similarity matrices. Our experiments on a Dutch folk song collection show that our segmentation results are comparable to the ones obtained by the reference-based method.